Movie IMDb Rating Predictor
EECS 349, Machine Learning
Zhilin Chen
Pre-procession of the dataset and why
In order to make this problem easier, we tried to classified the IMDb ratings to make this problem from a regression problem to a supervised classification problem. More specifically, we classified movies into five classes according to their IMDb ratings(r): S(8.5 ≤ r), A(7.5 ≤ r < 8.5), B(6.5 ≤ r ≤ 7.5), C(5.5≤ r ≤ 6.5) and F(r ≤ 5.5).
What's more, limited to small dataset, it's difficult to adapt any learning techniques on raw data as most of the attributes are consist of many different names while most of them only appear one or two times in the dataset. What's worse, this data set is far from enough to cover all the directors, writers or actors in movie industry, which could result in a bad performance of this predictor. Therefore, we going to turn all the nominal values into numerical values by substituting names with the average imdb ratings of the work they have involved in.
For more details of the processed data, please refer to the "screenshot of the processed data" under "Dataset" category.
Model selection and possible explanation
Before going deep into some learning techniques, we first use Weka and try different models and select the one with the highest accuracy(Correctly Classified Instances) in 10-folds cross-validation.
| Model | ZeroR | J48 | lazy.IB1 | lazy.IB5 | BayesNet | NaiveBayes | KStar | MultilayerPerceptron |
|---|---|---|---|---|---|---|---|---|
| Accuracy(%) | 38.62 | 72.35 | 60.13 | 62.71 | 82.02 | 79.05 | 70.52 | Takes too much time to run |
We could notice from the table above that both NaiveBayes and BayesNet could obtain satisfying accuracy on our task. ZeroR provides us a baseline of the accuracy we could achieve through learning. Obviously, our task is far away from "If-else-then" problem and it's much more complicated than simply splitting/filtering examples according to some attributes and then getting the right result. "K-Nearest-Neighbor" model in our task could be considered as "If some movie is close enough to K successful movies, then it would success". It makes sense, but it eventually obtain poor accuracy. It might because it's really difficult to figure out the proper "K". NaiveBayes returns a relatively high accuracy and provides us an acceptable explaination: "If some parts(such as directors, writers and actors) of the movie are good, the movie would be much more likely to success". This explaination could also justify the high accuracy of BayesNet, since each attribute would be related to other attributes in our problem.
Therefore, we choose BayesNet as the basic model for our predictor.
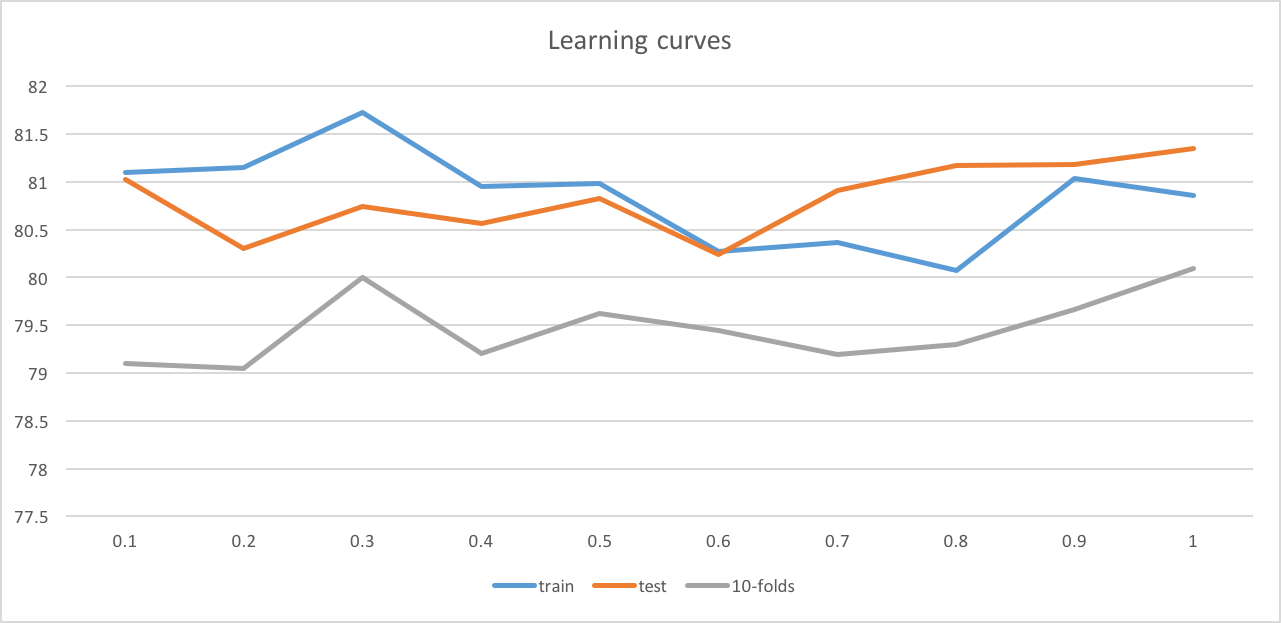
Learning curves
Then we go deep into BayesNet. We explore its accuracy on training set/ testing set/ 10-folds cross validation among the size of training set. We can notice from the chart below that these accuracies do not flucutuate too much. They are steady and close to each other. I consider it a successful result for the following reasons:
1) Our model has achieved really high accuracy(compared to only 38.62% in ZeroR) in out problem.
2) This model is steady as it seems that we don't need to worry about under-fitting and over-fitting problems.
3) When the training set is small, our model still can obtain satisfying accuracy on predicting the imdb ratings of given movie.