Movie IMDb Rating Predictor
EECS 349, Machine Learning
Zhilin Chen
Final Report
What is our task and motivation?
Movies, originally invented in the 1990s for entertainment, has now became an indispensable part of human culture. There are multiple criteria to define a “good” movie: if a movie profitable, popular or if it introduces new techniques in filmmaking. In my tasks, I’m going to adapt the rating of IMDb(Internet Movie Database) to define if a movie is “good” because it fairly reflects how public evaluate this movie.
Our task is to determine what and how attributes decide the IMDb rating of a movie. For example, how movie’s genre, director, stars or production corporation effect its IMDb ratings. This would be interesting and meaningful. A businessman would want to use it because he can know will a movie be popular and profitable beforehand. What’s else, this predictor could also provide us and relevant scholars how public preferences in movies change over time.
What is IMDb and IMDb ratings?
The Internet Movie Database (abbreviated IMDb) is an online database(www.imdb.com) of information related to films, television programs and video games, including cast, production crew, fictional characters, biographies, plot summaries, trivia and reviews. Actors and crew can post their own resume and upload photos of themselves for a yearly fee. U.S. users can view over 6,000 movies and television shows from CBS, Sony, and various independent filmmakers.
In IMDb voting system, each registered users can cast a vote(from 1 to 10) on every released title in the database. Users can vote as many times as they want but every vote will overwrite the previous one so it is one vote per title per user.
IMDb takes all the individual votes cast by IMDb registered users and use them to calculate a single rating and they don't use the arithmetic mean of the votes (although they do display the mean and average votes on the votes breakdown). IMDb displays weighted vote averages rather than raw data averages. Various filters are applied to the raw data in order to eliminate and reduce attempts at "vote stuffing" by individuals more interested in changing the current rating of a movie or TV show than giving their true opinion of it.
Although the raw mean and median are shown under the detailed vote breakdown graph on the ratings pages, the user rating vote displayed on a film / show's page is a weighted average. In order to avoid leaving the scheme open to abuse, IMDb does not disclose the exact methods used.
In a word, IMDb ratings could reflect HOW AUDIENCES LIKE THIS MOVIE
What is our goal and how does it make sense?
Each movie is jointly produced by Director, Writers, Actors and so on. These people (with their professional skills, specific understanding of movies and their audiences or any chemistry among them) and the content (some basic features such as Genres, Language and Country) could decide the quality of a movie (in terms of IMDb rating).
Therefore, in our task, we are going to predict the IMDb rating of movie with some given attributes.
Why is it important?
In general, this task would help:
1) provide businessmen who want to make profitable movies a guideline to choose the staffs.
2) provide us an insight into how the taste of audiences changes among years.
Where and how do we grab data?
1)The Open Movie Database(OMDb, http://www.omdbapi.com) API is a free web service to obtain movie. It provides us an API to access to the information of movies. Its search engine would return the information of target movie in JSON format like following:
{"Title":"Zootopia","Year":"2016","Rated":"PG","Released":"04 Mar 2016","Runtime":"108 min","Genre":"Animation, Action,
Adventure","Director":"Byron Howard, Rich Moore, Jared Bush","Writer":"Byron Howard (story by), Jared Bush (story by),
Rich Moore (story by), Josie Trinidad (story by), Jim Reardon (story by), Phil Johnston (story by),
Jennifer Lee (story by), Jared Bush (screenplay), Phil Johnston (screenplay)","Actors":"Ginnifer Goodwin, Jason Bateman,
Idris Elba, Jenny Slate", "Plot":"In a city of anthropomorphic animals, a rookie bunny cop and a cynical con artist
fox must work together to uncover a conspiracy.","Language":"English, Norwegian","Country":"USA","Awards":"1 nomination.",
"Poster":"http://ia.media-imdb.com/images/M/MV5BOTMyMjEyNzIzMV5BMl5BanBnXkFtZTgwNzIyNjU0NzE@._V1_SX300.jpg",
"Metascore":"78","imdbRating":"8.2","imdbVotes":"101,917","imdbID":"tt2948356","Type":"movie","Response":"True"}
2) Movie lists from wikipedia (https://en.wikipedia.org/wiki/Lists_of_films) and IMDb (ftp://ftp.funet.fi/pub/mirrors/ftp.imdb.com/pub/)
3) A self-written python program ( program github address? ) that will automatically grab the data from OMDb API of the movies in the given list and then store these datas in .csv files.
Description of dataset
1) Number of examples: 13427
2) Training and testing set: We randomly choose 10000 examples as training set and the remaining 3427 examples as testing set.
3) Attributes (since each movie might have multiple genres, writers, actors and so on, these attributes with multiple values would be split into multiple attributes, such as Genre_1, Genre_2, Genre_3...): 'Title', 'Year', 'Genre_1', 'Genre_2', 'Genre_3', 'Director', 'Writer_1', 'Writer_2', 'Writer_3', 'Actors_1', 'Actors_2', 'Actors_3', 'Actors_4', 'Metascore', 'imdbVotes', 'Language', 'Country' and 'imdbRatings'. And what should we notice is that NOT ALL the attributes have been used in learning (irrelevant attributes, such as 'Title' and 'imdbVotes' would be discarded during the learning).
4) Screenshot of raw data in .csv file:
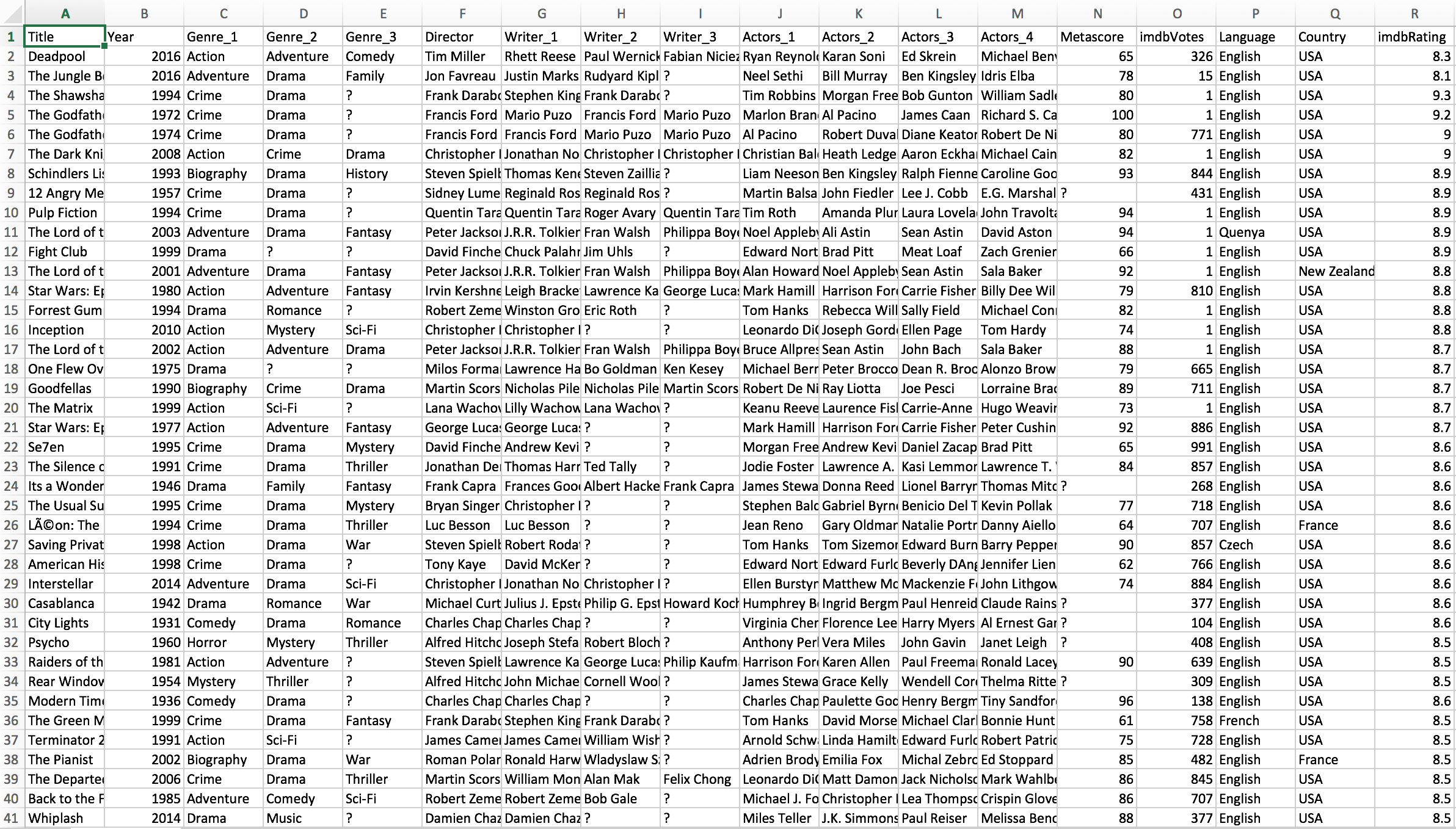
5) Screenshot of processed data in .csv file:

Why plain analysis?
Before using any machine learning techniques to predict the IMDb ratings of some movies, the raw data we've collected has already provided us many important information. For example, we could figure out the most successful/welcome writers/directors/actors/genres in specific years. These information could also provide us an insight of how the taste of audiences changes among years
Top K Genres/Directors/Writers/Actors between 2006 and 2010
These ratings depend on the average IMDb ratings of the related movies. It is simple but useful enough to provide us a basic knowledge of how these attributes affect the IMDb ratings. Following tables are the sample results we get from conducting plain analysis on raw data:
1)
| 2006 | 2007 | 2008 | 2009 | 2010 | |
|---|---|---|---|---|---|
| 1st | Documentary(7.22) | Biography(7.39) | War(7.25) | Short(7.52) | Documentary(7.48) |
| 2nd | War(7.08) | Documentary(7.30) | Biography(7.11) | War(7.15) | History(7.40) |
| 3rd | Short(7.07) | Music(7.25) | History(6.8) | Biography(7.02) | Biography(7.23) |
2)
| 2006 | 2007 | 2008 | 2009 | 2010 | |
|---|---|---|---|---|---|
| 1st | C. Nolan(8.5) | M. Loades(9.0) | C. Nolan(9.0) | A. Ruiz(8.7) | C. Nolan(8.8) |
| 2nd | J. Tusty(8.5) | A. Khan(8.5) | N. Pandey(8.4) | L. Psihoyos(8.5) | A. Kapadia(8.6) |
| 3rd | M. Scorsese(8.5) | J. Laurence(8.4) | A. Stanton(8.4) | R. Hirani(8.4) | V. Motwane(8.3) |
3)
| 2006 | 2007 | 2008 | 2009 | 2010 | |
|---|---|---|---|---|---|
| 1st | M. Majoros(8.5) | S. Kass(9.0) | J. Nolan(9.0) | A. Ruiz(8.7) | C. Nolan(8.8) |
| 2nd | J. Nolan(8.5) | A. Gupte(8.5) | C. Nolan(9.0) | M. Monroe(8.5) | M. Pandey(8.6) |
| 3rd | A. Mak(8.5) | S. Penn(8.2) | N. Pandey(8.4) | V. Chopra(8.4) | L. Unkrich(8.3) |
4)
| 2006 | 2007 | 2008 | 2009 | 2010 | |
|---|---|---|---|---|---|
| 1st | H. Jackman(7.32) | J. Brolin(7.69) | A. Jolie(7.36) | E. Bana(7.42) | M. Wahlberg(6.96) |
| 2nd | B. Willis(7.16) | M. Harden(7.23) | J. Black(7.00) | C. Plummer(7.40) | J. Baruchel(6.89) |
| 3rd | K. Winslet(7.06) | S. Labeouf(6.93) | D. Craig(6.89) | L. Endre(7.23) | R. Hall(6.86) |
5)
| Genres | Directors | Writers | Actors | |
|---|---|---|---|---|
| 1st | Biography(7.11) | C. Nolan(8.77) | C. Nolan(8.83) | M. Caine(8.15) |
| 2nd | War(7.07) | M. Scorsese(7.93) | J. Lindqvist(7.6) | A. Khan(7.96) |
| 3rd | Documentary(7.05) | D. Fincher(7.73) | A. Jensen(7.58) | C. Bale(7.8) |
| 4th | History(6.93) | S. Bier(7.56) | D. Cohen(7.4) | L. DiCaprio(7.78) |
| 5th | Short(6.71) | D. Yates(7.56) | M. Groening(7.39) | M. Ruffalo(7.57) |
How average IMDb ratings goes among years?
We can notice from the image below that annual average IMDb ratings would fluctuate around 6.3. 1992 could be considered as the 'golden year' of movies. What's more, we are witnessing a downward trend of IMDb ratings, which could indicates that the audiences are more fastidious about movies or that the current movies are worse than decades before

Pre-procession of the dataset and why
In order to make this problem easier, we tried to classified the IMDb ratings to make this problem from a regression problem to a supervised classification problem. More specifically, we classified movies into five classes according to their IMDb ratings(r): S(8.5 ≤ r), A(7.5 ≤ r < 8.5), B(6.5 ≤ r ≤ 7.5), C(5.5≤ r ≤ 6.5) and F(r ≤ 5.5).
What's more, limited to small dataset, it's difficult to adapt any learning techniques on raw data as most of the attributes are consist of many different names while most of them only appear one or two times in the dataset. What's worse, this data set is far from enough to cover all the directors, writers or actors in movie industry, which could result in a bad performance of this predictor. Therefore, we going to turn all the nominal values into numerical values by substituting names with the average imdb ratings of the work they have involved in.
For more details of the processed data, please refer to the "screenshot of the processed data" under "Dataset" category.
Model selection and possible explanation
Before going deep into some learning techniques, we first use Weka and try different models and select the one with the highest accuracy(Correctly Classified Instances) in 10-folds cross-validation.
| Model | ZeroR | J48 | lazy.IB1 | lazy.IB5 | BayesNet | NaiveBayes | KStar | MultilayerPerceptron |
|---|---|---|---|---|---|---|---|---|
| Accuracy(%) | 38.62 | 72.35 | 60.13 | 62.71 | 82.02 | 79.05 | 70.52 | Takes too much time to run |
We could notice from the table above that both NaiveBayes and BayesNet could obtain satisfying accuracy on our task. ZeroR provides us a baseline of the accuracy we could achieve through learning. Obviously, our task is far away from "If-else-then" problem and it's much more complicated than simply splitting/filtering examples according to some attributes and then getting the right result. "K-Nearest-Neighbor" model in our task could be considered as "If some movie is close enough to K successful movies, then it would success". It makes sense, but it eventually obtain poor accuracy. It might because it's really difficult to figure out the proper "K". NaiveBayes returns a relatively high accuracy and provides us an acceptable explaination: "If some parts(such as directors, writers and actors) of the movie are good, the movie would be much more likely to success". This explaination could also justify the high accuracy of BayesNet, since each attribute would be related to other attributes in our problem.
Therefore, we choose BayesNet as the basic model for our predictor.
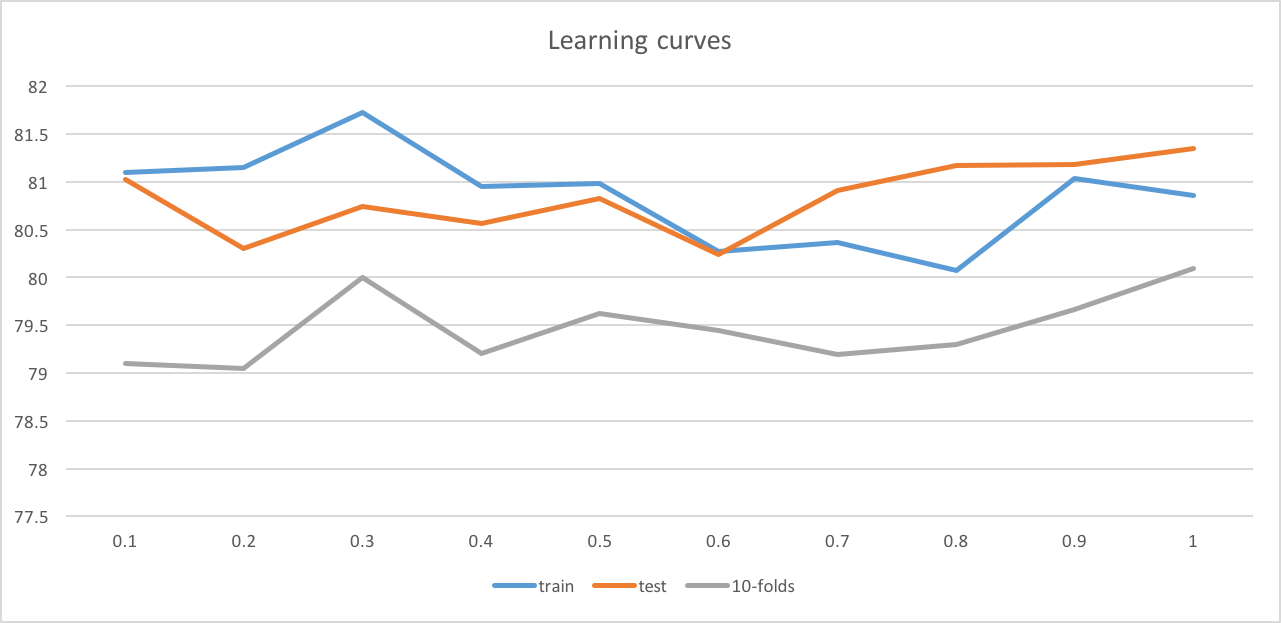
Learning curves
Then we go deep into BayesNet. We explore its accuracy on training set/ testing set/ 10-folds cross validation among the size of training set. We can notice from the chart below that these accuracies do not flucutuate too much. They are steady and close to each other. I consider it a successful result for the following reasons:
1) Our model has achieved really high accuracy(compared to only 38.62% in ZeroR) in out problem.
2) This model is steady as it seems that we don't need to worry about under-fitting and over-fitting problems.
3) When the training set is small, our model still can obtain satisfying accuracy on predicting the imdb ratings of given movie.
Conclusion
Generally speaking, we are really successful in our predictor for the following reason:
1) Plain analysis provides us important and enough insight of the current movie industry. For example, top K genres/directors/writers/actors in specific years/period.
2) Our model has achieved really high accuracy(compared to only 38.62% in ZeroR) in out problem.
3) This model is steady as it seems that we don't need to worry about under-fitting and over-fitting problems.
4) When the training set is small, our model still can obtain satisfying accuracy on predicting the imdb ratings of given movie.
Suggestion for future work
We should keep enlarging the dataset for our predicator. We believe that if it's large enough, we are able to achieve satisfying result withou any pre-procession and we might figure out relation between specific writers/actors/diretors with the IMDb ratings.
In our problem, we treat it as classification problem. It would be better if we could treat it a regression problem and then figure out a more specific model to predict the exact IMDb rating of movie.